
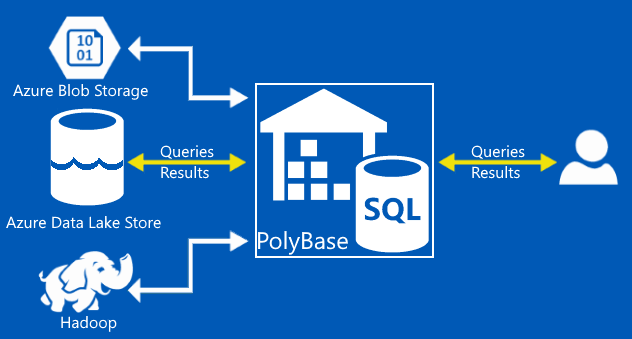
Using Polybase, the Azure Data Warehouse (ADW) is able to access semi-structured data located in Azure blob storage (WASB) or, as this blog will cover, in Azure Data Lake Store (ADLS).
This is similar to how Apache Hive in Hadoop is able to use semi-structured data using SerDe‘s.
Polybase should be pointed to a directory containing a collection of same-structure files. These can be in further sub directories since Polybase will recursively descend and glob all the files under the directory.
Components
First off, know that this will only work with the Azure Data Warehouse. Polybase can access data in blob storage only when using SQL Server 2016, accessing ADLS requires the use of the Data warehouse.
Setting this all up requires the creation of a number of objects:
- Security credentials to access the storage.
- This will require a master key and a scoped credential.
- The external data source.
- For this blog, we will be using an ADLS source.
- The external file format the semi structured data has.
- At this time, Polybase has support for delimited text (csv), RCFile, ORC and Parquet. Sadly, no JSON.
- The external table.
- This will be the logical table SQL queries can be run against.
Connect to the Data Warehouse in Azure
A data warehouse should already be running in Azure. Use any SQL GUI to connect to it. I will be using SQL Server Management Studio (SSMS), but anything that works is fine. (Make certain the Azure firewall allows access to the DW.)
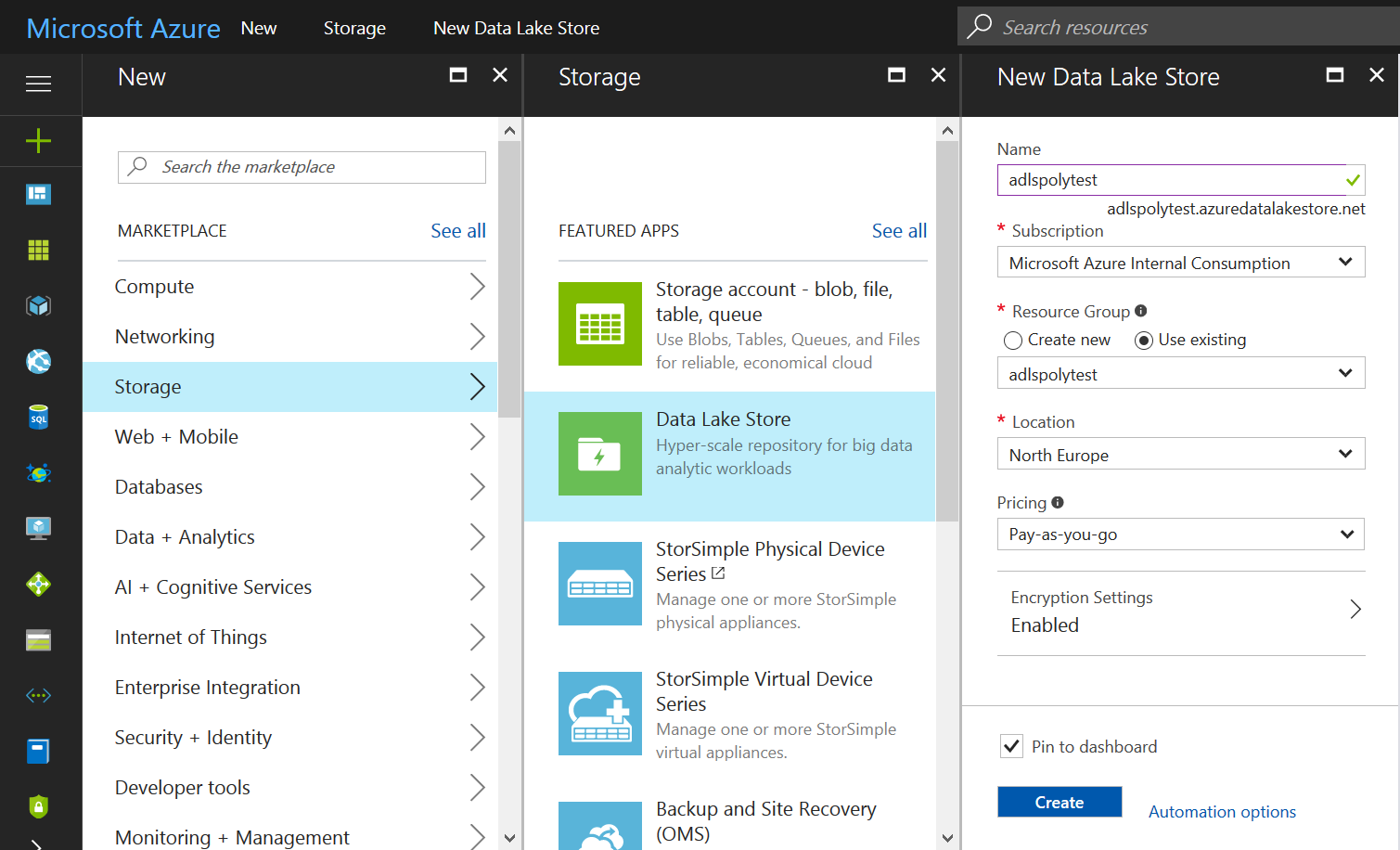
Create an Azure Data Lake Store
An Azure Data Lake Store is the second part needed so there is somewhere to put the data in. Simply use the Azure portal to create it.
 Upload data to ADLS
Upload data to ADLS
I used the files in the Ambulance Data folder from the Azure Data Lake Git Repository.
Uploading the files to ADLS can be done several ways. The easiest way is to use the Data Explorer included in the ADLS management pages on the Azure portal. Just create a new directory and upload all the files in there.
Click the “Data Explorer” link on the ADLS management page in the Azure portal.
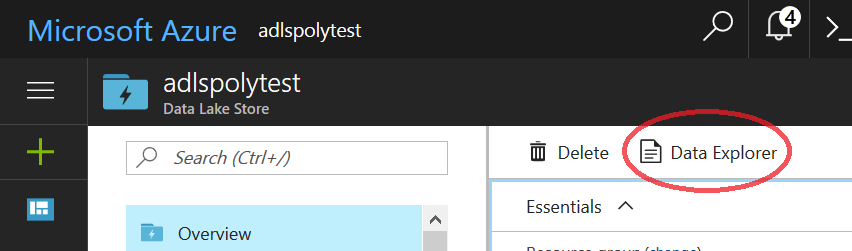 Create a new sub directory to place the data files in.
Create a new sub directory to place the data files in.
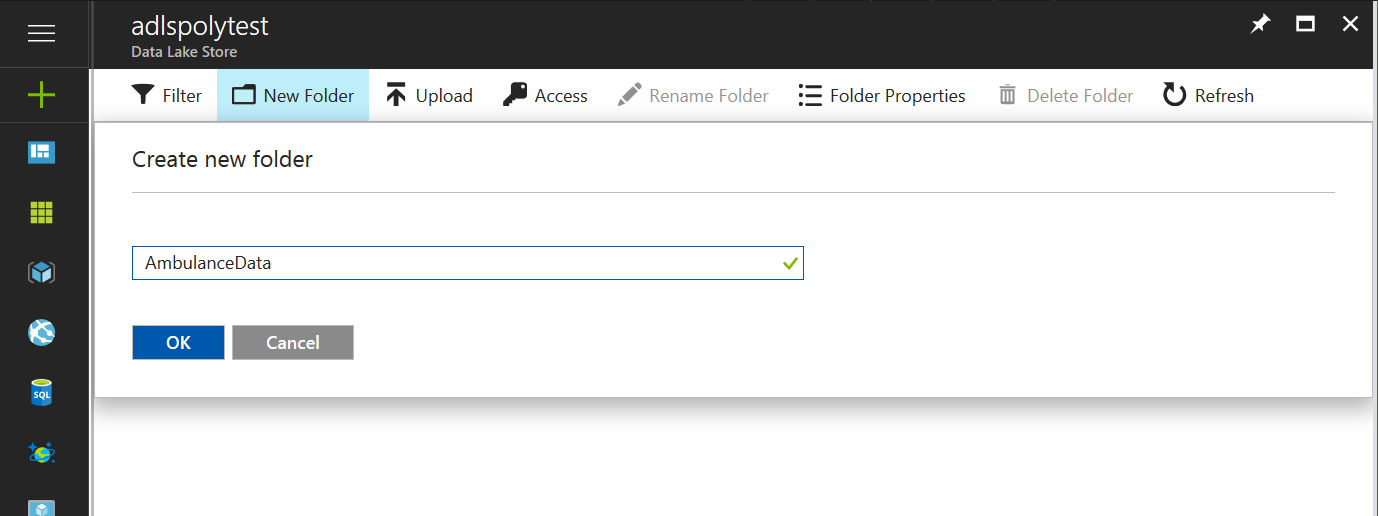 Click the Upload link to upload the data.
Click the Upload link to upload the data.
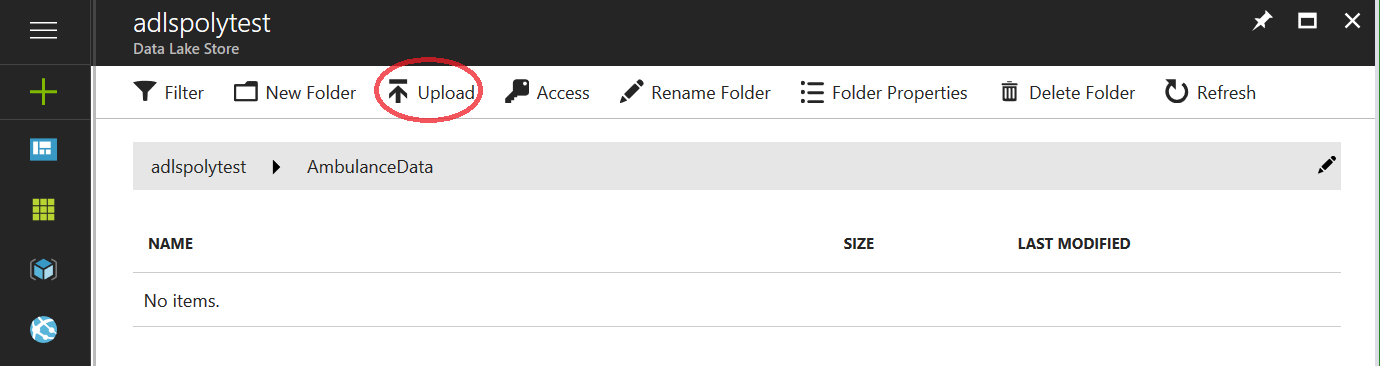 Using the file selector icon, select all the vehicle_*.csv files you want to upload and click the “Add selected files” button. The “Drivers.txt” and “DriverShiftTrips.csv” files have a different format and will cause problems.
Using the file selector icon, select all the vehicle_*.csv files you want to upload and click the “Add selected files” button. The “Drivers.txt” and “DriverShiftTrips.csv” files have a different format and will cause problems.
 All the selected files will now be uploaded. Depending on the size of the data and the upload speed available, this can take some time.
All the selected files will now be uploaded. Depending on the size of the data and the upload speed available, this can take some time.
The online documentation has more information on using the Data Lake Store using the portal, Powershell or any of the available SDKs (.Net, Java, Rest API, Azure CLI, Node.js, Python).
Azure AD web application for Authentication
To access the ADLS from the Azure Data Warehouse, an Azure AD web application for service-to-service authentication is required. (online documentation.) (For those that are familiar to kerberos, think of these AD Applications as Kerberos Service principals.)
Go to the Active Directory management section in the Azure portal. In “App registration”, click the “+ New application registration” link at the top of the page.
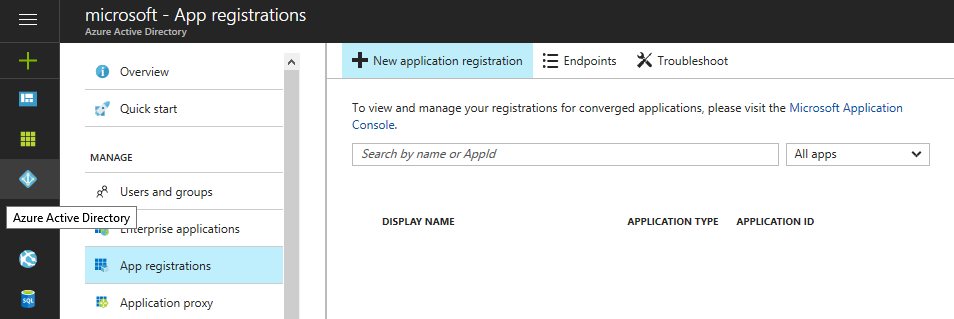 In the small form, give the app a unique name and make sure that the Application type is set to “Web App / API”. Since the “Sign-on URL” will not be used for this app, set it to any valid URL expression. Click the “Create” button.
In the small form, give the app a unique name and make sure that the Application type is set to “Web App / API”. Since the “Sign-on URL” will not be used for this app, set it to any valid URL expression. Click the “Create” button.
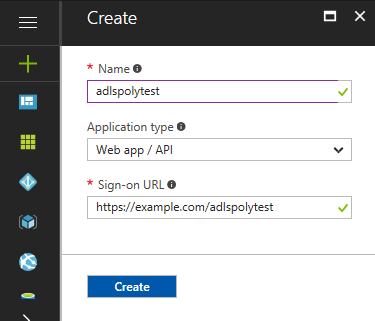 Search for the newly creates app in the list and click on it to get the needed credentials.
Search for the newly creates app in the list and click on it to get the needed credentials.
 The first credential needed is the application ID. It can be found in the “Essentials” information.
The first credential needed is the application ID. It can be found in the “Essentials” information.
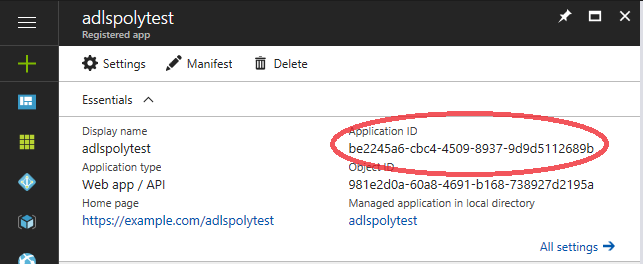 For the second part of the credentials, a new Key must be created. Click on the “Keys” link, complete the “Key description” and “Duration” fields and click the “Save” button at the top of the page. As the warning explains, make sure to copy and save the value that was generated before continuing.
For the second part of the credentials, a new Key must be created. Click on the “Keys” link, complete the “Key description” and “Duration” fields and click the “Save” button at the top of the page. As the warning explains, make sure to copy and save the value that was generated before continuing.
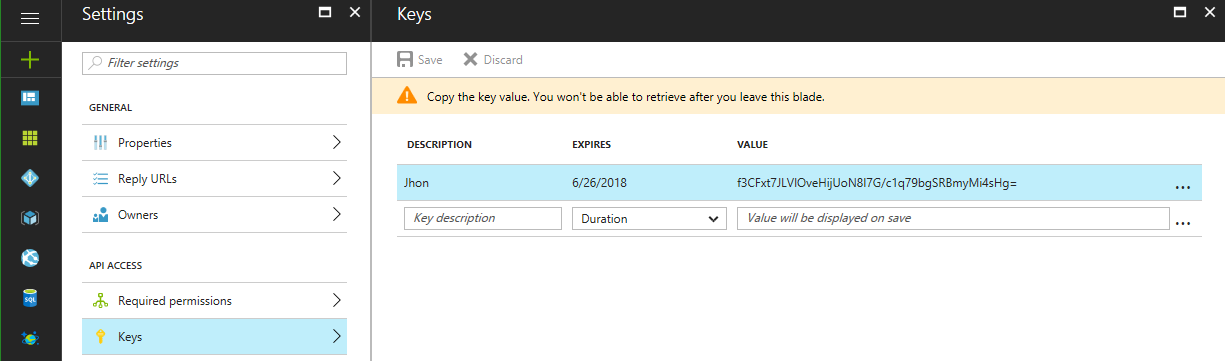 The last part, the tenant ID, can be found in the Active Directory information under “Properties”. Look for the “Directory ID”.
The last part, the tenant ID, can be found in the Active Directory information under “Properties”. Look for the “Directory ID”.
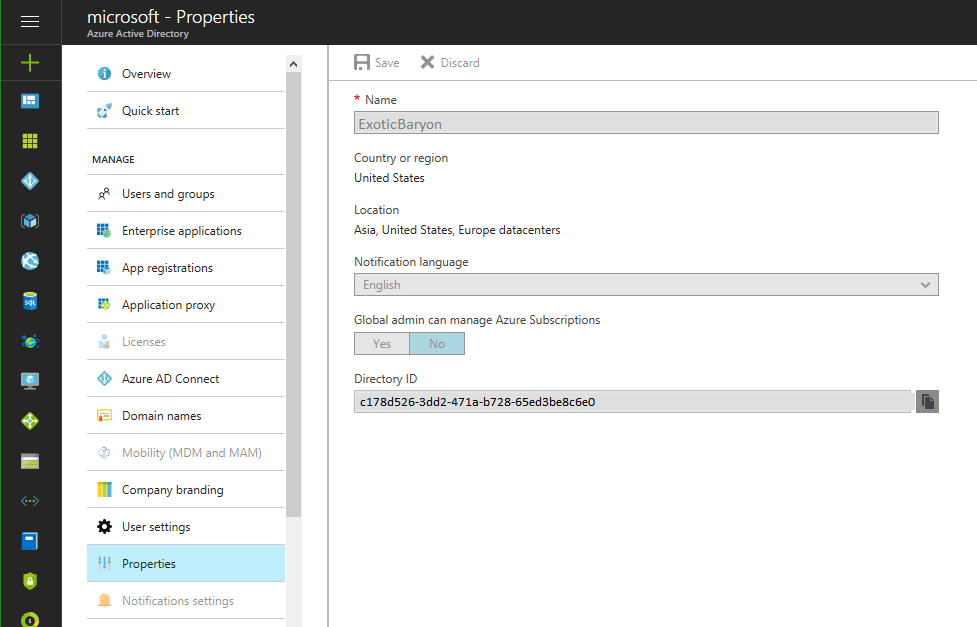 Using the tenant ID, an OAuth 2.0 token endpoint can be created: https://login.windows.net/<tennantID>/oauth2/token (This endpoint string can also be found in the Azure portal in the AD management pages under the “Endpoints” link.)
Using the tenant ID, an OAuth 2.0 token endpoint can be created: https://login.windows.net/<tennantID>/oauth2/token (This endpoint string can also be found in the Azure portal in the AD management pages under the “Endpoints” link.)
From the examples above, the three strings required for authentication are:
App ID: be2245a6-cbc4-4509-8937-9d9d5112689b
Auth key: f3CFxt7JLVlOveHijUoN8I7G/c1q79bgSRBmyMi4sHg=
OAuth: https://login.windows.net/c178d526-3dd2-471a-
b728-65ed3be8c6e0/oauth2/token
Keep these credentials handy somewhere, they will be needed in a bit.
Assigning the AD App to the ADLS folder
As is often the case, securing the environment is taking quite a bit of work, but fortunately, we are almost done. The next step is to assign the AD application just created to the directory holding the data. (The ability to assign a specific AD Application to a directory this way, makes securing ADS very granular.)
Go to the ADLS management pages in the Azure portal and go to the Data Explorer and select the folder containing the data files. Click on the “Access” link.
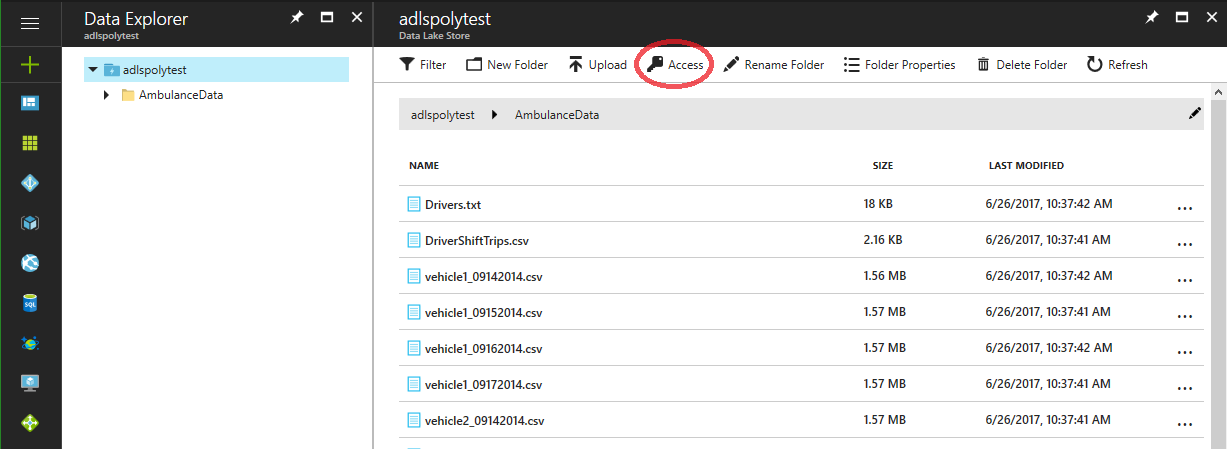 Now click the “+ Add” link to add a new custom ACL.
Now click the “+ Add” link to add a new custom ACL.
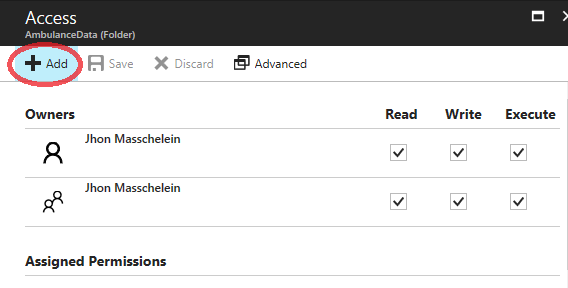 In the “Select User or Group” blade, search for the AD Application that was created earlier and select it.
In the “Select User or Group” blade, search for the AD Application that was created earlier and select it.
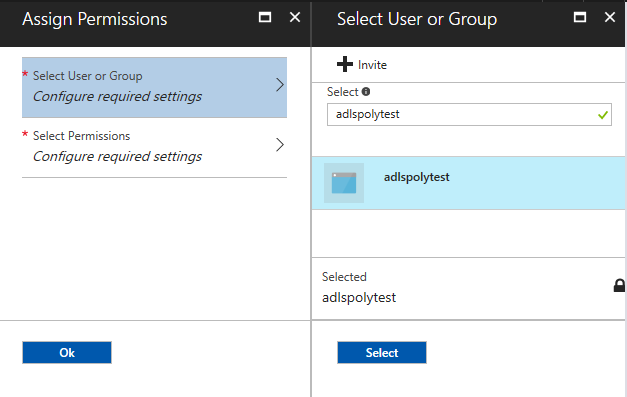 And in the “Select Permissions” blade, set the ACL you want to assign to the Application. In this example, full rights are given to the directory and everything in it.
And in the “Select Permissions” blade, set the ACL you want to assign to the Application. In this example, full rights are given to the directory and everything in it.
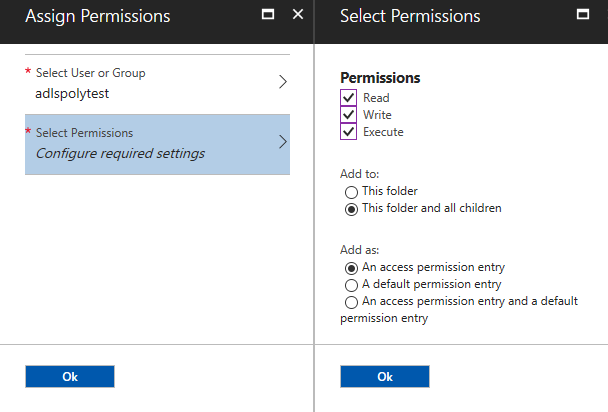 After accepting those settings, you should now see the news permission added to the access list.
After accepting those settings, you should now see the news permission added to the access list.
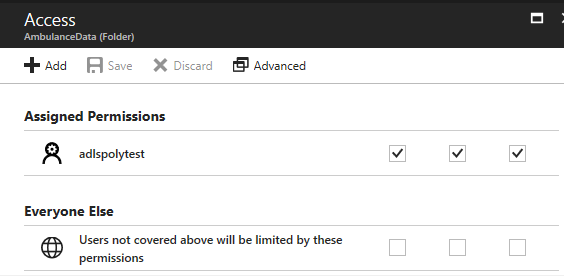 However, even though the adlspolytest credential now has full access to the AmbulanceData subdirectory, it does not have any access to the root of the ADLS store itself. That means that any access to the sub directory will fail unless at least the “execute” permission is given to the adlspolytest credential for the ADLS root.
However, even though the adlspolytest credential now has full access to the AmbulanceData subdirectory, it does not have any access to the root of the ADLS store itself. That means that any access to the sub directory will fail unless at least the “execute” permission is given to the adlspolytest credential for the ADLS root.
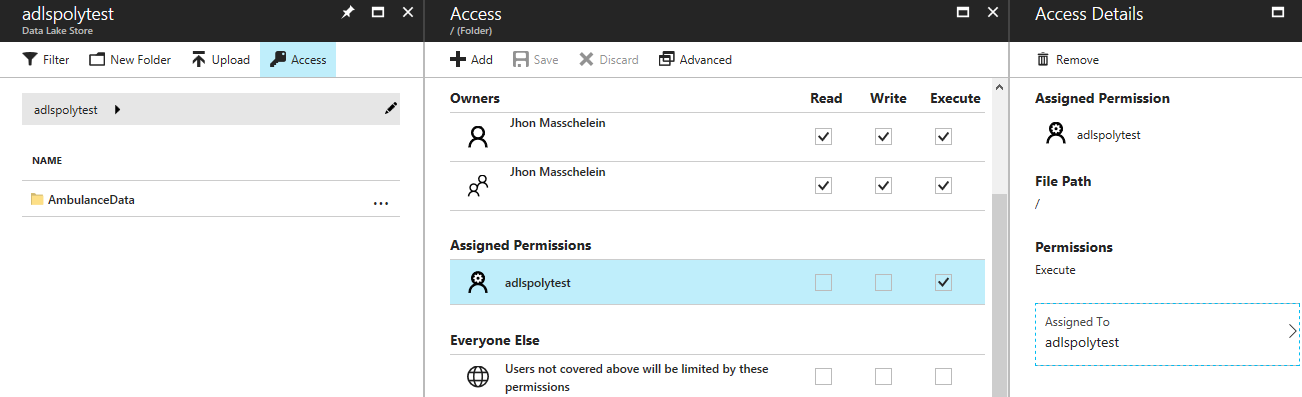 So the previous steps need to be repeated, setting an “execute”-only ACL on the root location of the adlspolytest store. The permissions should not be handed down to the children of the root directory since full permissions were already applied tot he AmbulanceData sub directory and its descendants.
So the previous steps need to be repeated, setting an “execute”-only ACL on the root location of the adlspolytest store. The permissions should not be handed down to the children of the root directory since full permissions were already applied tot he AmbulanceData sub directory and its descendants.
Polybase
Once the data is uploaded and the authentication credentials are created, the different components can be created in the Azure Data Warehouse. In SSMS, open a new Query script window to run the scriptlets that follow.
1. Security Credentials
First, a new database master key is needed if there is not one available yet. (More info) It will not be references in the rest of this blog, but a master key is used for all encryption on the databases.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
Now create a Scoped Database Credential which will be used to access the storage. Here is where the credential strings created earlier are used.
CREATE DATABASE SCOPED CREDENTIAL ADL_User WITH IDENTITY = 'be2245a6-cbc4-4509-8937-9d9d5112689b@https://login.windows.net/c178d526-3dd2-471a-b728-65ed3be8c6e0/oauth2/token', SECRET = 'f3CFxt7JLVlOveHijUoN8I7G/c1q79bgSRBmyMi4sHg=';
The blue part is the Application ID, the green part is the OAuth 2.0 Endpoint and the red part is the security key value.
2. External Data Source
Define a connection to the Data Lake Store using the Scoped Credential created above.
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore WITH ( TYPE = HADOOP, LOCATION = 'adl://adlspolytest.azuredatalakestore.net', CREDENTIAL = ADL_User );
The blue part is the ADL URI. It can be found on the ADLS management pages in the Azure Portal. It is quite easy to figure out though, since it is simply the name given to the ADLS followed by the standard azuredatalakestore.net domain. The green string is of course the name of the scoped credential created in the previous step.
3. External File Format
The external file format definition can be quite complex (online documentation). However, the vehicle datafiles are simple column delimited files so the definition here can remain simple.
CREATE EXTERNAL FILE FORMAT TextFileFormat WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR =',',
STRING_DELIMITER = '"',
USE_TYPE_DEFAULT = TRUE)
);
4. External Table
We are getting close now! Here the external table is defined. This table will be visible in the Data Warehouse and queries can be run against it. But the table will not store any data: all data will be read from the raw data in the Data Lake Store.
CREATE EXTERNAL TABLE [dbo].[Ambulance_Data] (
[vehicle_id] int,
[entry_id] bigint,
[event_date] DateTime,
[latitude] float,
[longitude] float,
[speed] int,
[direction] char(5),
[trip_id] int
)
WITH (LOCATION='/AmbulanceData/',
DATA_SOURCE = AzureDataLakeStore,
FILE_FORMAT = TextFileFormat
);
As can be expected, the full table schema is described in the table declaration and in the second part, the different objects defined earlier are used to tell Polybase how to get to the data for this external table.
This is also the point where any problems will present themselves. If the credetntials are bad, the ACLs are badly placed or the data files have issues, here is where the errors will be shown. This does make it hard to debug any challenges. Fortunately, the java errors that are returned usually give a reasonable idea of the problem.
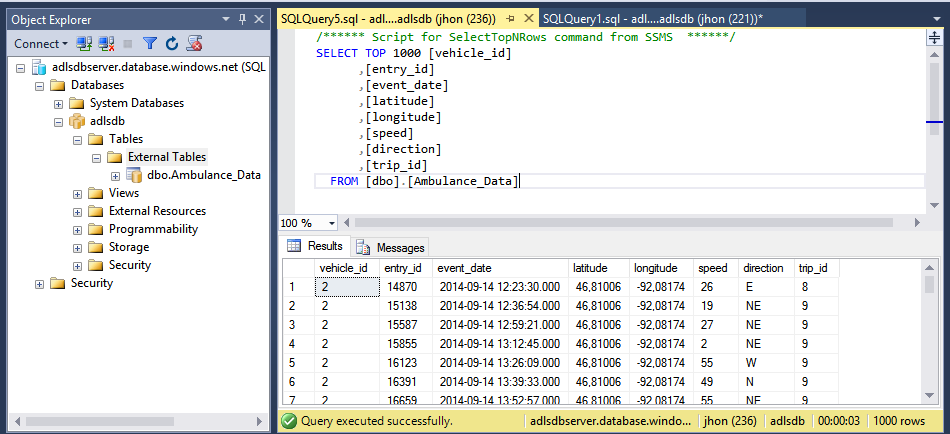
Query the data
The table is created so feel free to use normal T-SQL to query the data. Do note that SSMS will show the table under the “External Tables” heading.
 Do feel free to leave any comments below!
Do feel free to leave any comments below!
The Full T-SQL Script
--1: Security Credentials -- Create a master key on the database. -- Required to encrypt the credential secret. CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo'; -- Create a database scoped credential for Azure Datalake Store. -- IDENTITY: The AD Application ID with the OAuth 2.0 endpoint. -- SECRET: The AD application authentication key value. CREATE DATABASE SCOPED CREDENTIAL ADL_User WITH IDENTITY = 'be2245a6-cbc4-4509-8937-9d9d5112689b@https://login.windows.net/c178d526-3dd2-471a-b728-65ed3be8c6e0/oauth2/token', SECRET = 'f3CFxt7JLVlOveHijUoN8I7G/c1q79bgSRBmyMi4sHg='; --2: Create an external data source. -- LOCATION: Azure datalake name. -- CREDENTIAL: The database scoped credential created above. CREATE EXTERNAL DATA SOURCE AzureDataLakeStore WITH ( TYPE = HADOOP, LOCATION = 'adl://adlspolytest.azuredatalakestore.net', CREDENTIAL = ADL_User ); --3: Create an external file format. -- FORMAT TYPE: Type of format in Hadoop (DELIMITEDTEXT, RCFILE, ORC, PARQUET). CREATE EXTERNAL FILE FORMAT TextFileFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR =',', STRING_DELIMITER = '"', USE_TYPE_DEFAULT = TRUE) ); --4: Create an external table. -- LOCATION: Folder under the ADLS root folder. -- DATA_SOURCE: Specifies which Data Source Object to use. -- FILE_FORMAT: Specifies which File Format Object to use -- REJECT_TYPE: Specifies how you want to deal with rejected rows. Either Value or percentage of the total -- REJECT_VALUE: Sets the Reject value based on the reject type. -- REJECT_SAMPLE_VALUE: The number of rows to retrieve before the percentage of rejected rows is calculated. CREATE EXTERNAL TABLE [dbo].[Ambulance_Data] ( [vehicle_id] int, [entry_id] bigint, [event_date] DateTime, [latitude] float, [longitude] float, [speed] int, [direction] char(5), [trip_id] int ) WITH (LOCATION='/AmbulanceData/', DATA_SOURCE = AzureDataLakeStore, FILE_FORMAT = TextFileFormat );
Thanks! I was flailing to cobble together this information from various other sources. Your post wrapped everything up nicely and turned out to be the only one I needed.
I am getting this error while creating the external data source. Could you please guide me to solve the issue.
Scheme of the input URI is not supported. Please revise the following scheme and try again: ‘adl’
I am using below statement
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (
TYPE = HADOOP,
LOCATION = ‘adl://azdlgen1.azuredatalakestore.net’,
CREDENTIAL = ADLCredential
);
is it because of any port block or similar?
The error “Scheme of the input URI is not supported” does not look like a blocked port to me.
Looking at the docs (https://docs.microsoft.com/en-us/sql/t-sql/statements/create-external-data-source-transact-sql?view=sql-server-2017) there have been some changes to the syntax with ADLSGen2 going into preview.
Assuming you are using a Gen1 ADLS (which your account name seems to indicate) it looks like the URL is no longer “*.azuredatalakestore.net” but “*.azuredatalake.net”, without the “store” part. Can you check in your ADLS dashboard and see if that is the URL you should be using?
If you are using the ADLSGen2 version, than adl is the wrong protocol prefix, you should use the abfs prefix, as explained in the doc page.
Let me know if you still cannot get it to work?
I do get the identical error as Abison. I did verify your (Jhon’s) comments:
* Data Lake Storage Gen1
* ADLS dashboard returns adl://+++++.azuredatalakestore.net
but
CREATE EXTERNAL DATA SOURCE AzureDataLakeStorageGen1
WITH (
TYPE = HADOOP,
LOCATION = ‘adl://+++++.azuredatalake.net’,
CREDENTIAL = ADLSG1Credential
);
keeps giving the “Scheme of the input URI is not supported. Please revise the following scheme and try again: ‘adl'” error.
I also tried with the prefix for Gen2 (abfs), but no glory 🙁
Anyone any clue?
Meanwhile, updated also to latest build of SSMS.
Tried also all (0 – 8) of the config values with
EXEC sp_configure @configname = ‘hadoop connectivity’, @configvalue = 7;
GO
RECONFIGURE
GO
SSMS keeps on accepting only HDFS-uri.
Alright, I just tested the instructions in the blog on my Azure account and it all “just works”. (I only tested ADLSGen1 because Gen2 is still in preview.)
FYI: my earlier reply about the change in URI for data lake store, though correct, is not relevant since the old URI still works fine.
So the only thing I can think is going wrong for you is that you are not using an Azure Data Warehouse?
As I mention at the top of the blog, ADLS over Polybase only works for Azure Data Warehouse.
Hi,
Other than creating an external table, is there a way to query a file in DLS like select * from file_in_dls?
Thanks,
Prashanth
Short answer: Yes.
Long answer: even though traditionally Polybase was used pretty much exclusively for CTAS operations, this was due to a limitation in Polybase: it did not do predicate push-down.
So even though you can perfectly do a “select * from”, it would likely have been a costly operation since any “where x=y” would only have been applied after the entire table was loaded in the ADW. So you wanted to retrieve one row where id=1? Well, Polybase will copy the entire table to the ADW and then do the selection of the one row. In the past I never advised to use Polybase for anything but CTAS.
However, things are changing: the new SQL server 2019 Big Data clusters use Polybase under the hood and while this is still in preview I believe, the available documentation at least heavily implies that Polybase now does indeed do predicate push-down (and more).
Here are some links with more info: (The whitepaper especially is quite interesting)
docs: https://docs.microsoft.com/en-us/sql/relational-databases/polybase/polybase-guide?view=sqlallproducts-allversions
whitepaper: https://info.microsoft.com/rs/157-GQE-382/images/EN-US-CNTNT-white-paper-DBMod-Microsoft-SQL-Server-2019-Technical-white-paper.pdf
So I have not tested this yet, so no guarantees, but with the new Polybase, using virtual tables as if they were regular tables should be perfectly fine.
However, re-reading you question, I’m not sure I am actually answering it, so let’s try again. 🙂
If you want to use SQL to query data, you will need to have something resembling a database table and using Polybase, you can use Azure Data Warehouse to query files on ADLS as if they were a table.
You need to tell the database execution engine how to get to the data file in a secure way and how to interpret it as if it was a database table. And that is why you pretty much need to create a virtual table to get this to work.
Looking at Hadoop, you would do pretty much the same thing using SerDe’s to add virtual tables to Apache Hive.
Do let me know If I’m still not hitting the mark with this answer! 🙂
Hi Jhon, Thanks for your post. I am trying with Parquet file as below and successfully created the external table. But When I am trying to read from external table, facing data type exception
CREATE EXTERNAL FILE FORMAT parquetfile
WITH (
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION =’org.apache.hadoop.io.compress.GzipCodec’
);
Error Message:
HdfsBridge::recordReaderFillBuffer – Unexpected error encountered filling record reader buffer: ClassCastException: parquet.io.api.Binary$ByteArraySliceBackedBinary cannot be cast to java.base/java.lang.Integer
Any thoughts?
A cast exception will be the result of a mismatch between the data-types you used in the create table command. That is where you define the schema for the new table and it needs to match the data that is in the parquet file.
Now I have not used the Parquet file-format myself yet so I cannot speak form experience, but there can definitely be some funky type conversion issues.
If you can give me the create table command you used and the schema definition of the Parquet file, I can dig a little deeper for you?
Hey Jhon,
This blog was very informative. Thank you.
We are using Data lake Gen 2 and Azure Data Warehouse and followed your blog and we are getting the following error on creating external table code:
Msg 105019, Level 16, State 1, Line 36
EXTERNAL TABLE access failed due to internal error: ‘Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:
HdfsBridge::isDirExist – Unexpected error encountered checking whether directoy exists or not: ADLException: Error getting info for file /Company
Operation GETFILESTATUS failed with HTTP401 : null
Last encountered exception thrown after 5 tries. [HTTP401(null),HTTP401(null),HTTP401(null),HTTP401(null),HTTP401(null)]
[ServerRequestId:86b4479c-001f-0065-3f1d-dd8d97000000]’
We are using “adl://” and “.dfs.core.windows.net/” when creating external data source.
Also, we are seeing Authorization error on Azure Portal under the storage account every time we are trying to create an external table. That coincides with the HTTP 401 error (5 retries) but we are not able to figure it out why?
It’s a bit hard to diagnose with the limited info, but I’ll give it a try.
The error seems to indicate that the directory path you provide is not found or not accessible. Considering you get access denied errors, that would be my best guess. Have you made sure that the service principal you are using has full access permissions to the directory and the file(s) in it?
For the directory (and the parents) yuo’llneed at least read and execute, for the file(s) you’ll at least need read.
It’s a good idea to check and set the default permissions n the directory as well, just in case any new files get created there.
Hi Jhon
Do you confirm your identity don’t have “\”? I get below error when I don’t use “\”.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = ‘@\’,
SECRET = ” ;
Failed to execute query. Error: External file access failed due to internal error: ‘Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:
HdfsBridge::isDirExist – Unexpected error encountered checking whether directory exists or not: IOException: Server returned HTTP response code: 400 for URL: https://login.microsoftonline.com/xxxxxxxxxxxxxxxxxx/oauth2/v2.0/token‘
But I also get the below error when I use ‘@\’
External file access failed due to internal error: ‘Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:
HdfsBridge::isDirExist – Unexpected error encountered checking whether directory exists or not: MalformedURLException: no protocol: \https://login.microsoftonline.com/xxxxxxxxxxxxxx/oauth2/v2.0/token’
Any thoughts?
Hi Shuai
The ‘/’ is definitely not needed there. the identity is your application ID followed by ‘@’ and then the URI where the oauth endpoint is located. That endpoint needs to be a valid https URL so definitely no ‘/’ before the ‘https://’.
This is also the error you get when you try to add the slash: a malformed https URI.
Now the problem with your first version (the one without the ‘/’): it is able to connect to the hostname you have in the URI (https://login.microsoftonline.com) but then tries to access the directory on that server (/xxxxxxxxxxxxxxxxxx/oauth2/v2.0/token) and cannot find that one, giving you the “isDirExist ” error.
Now this blog is a bit old so I cannot guarantee nothing changed, but I used ‘https://login.windows.net’ as the host part of the URI where you are using ‘https://login.microsoftonline.com’.
Again I am not sure if things have changed and I am not able to check it for you now, but the error does indicate that the URI you are using to access the oauth endpoint is invalid… Have you tried a version with the hostname ‘https://login.windows.net’ as I use in the example?
Regards,
Jhon
In case someone else runs into this…
We had the exact same problem today and our issue was choosing the “v2” endpoint from the App Registration’s Endpoints page. Seems SQL DW doesn’t know how to use that but one has to use the “v1” URI instead.
I.e. the IDENTITY string in the database scoped credential has to be like “@https://login.microsoftonline.com/xxxxxxxxxxxxxxxxxx/oauth2/token” without the “v2.0” part inline.
Thanks for sharing!
When using Polybase to connect to ADLS files using SQL endpoint, does this allow Update and Insert options as well? Can i update the data present in the ADLS file using conventional SQL command?